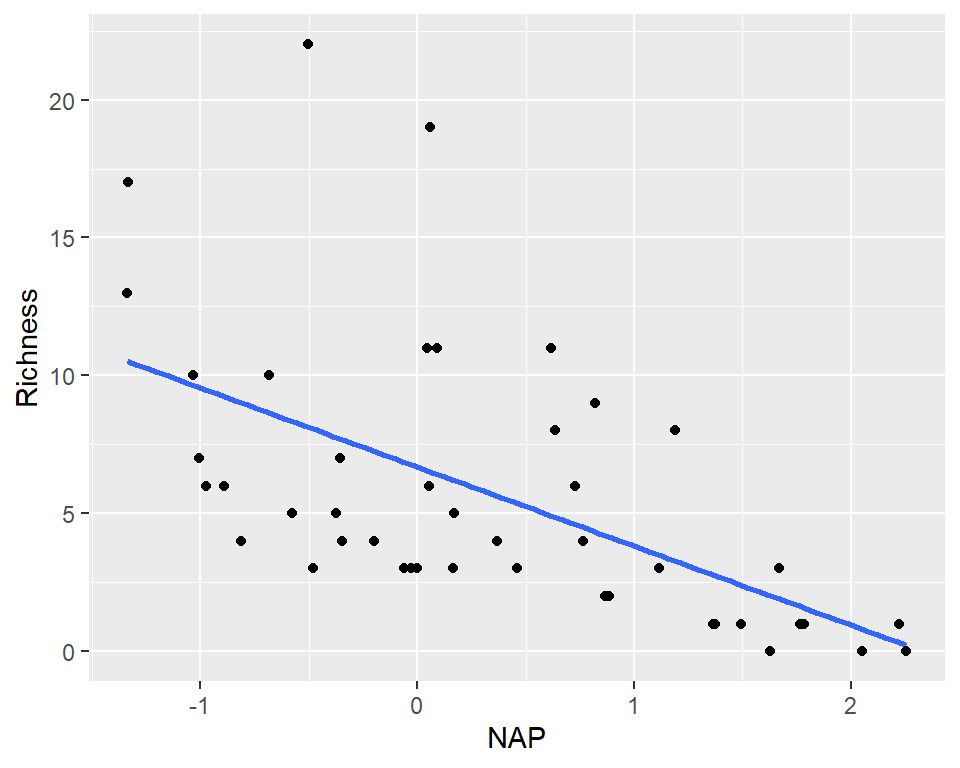
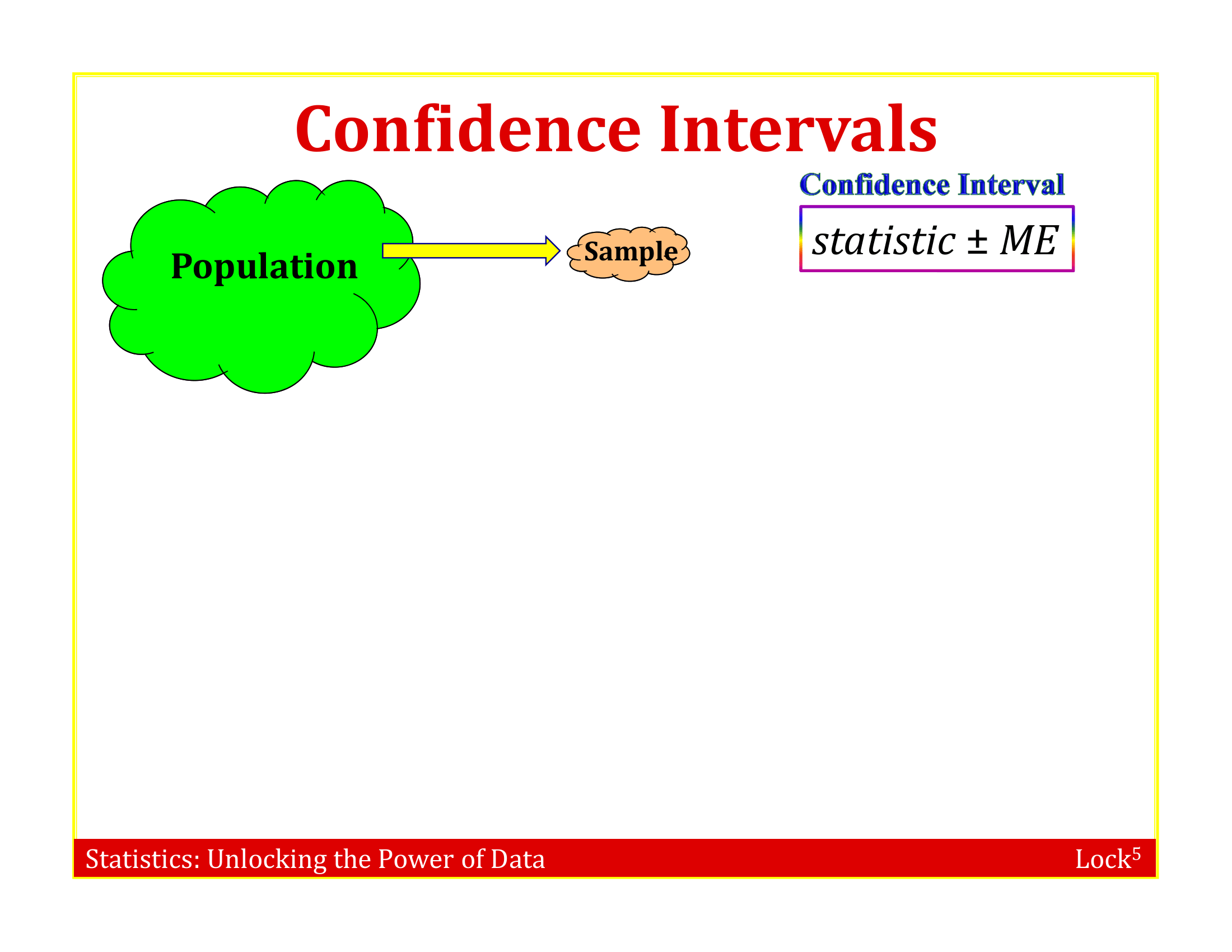
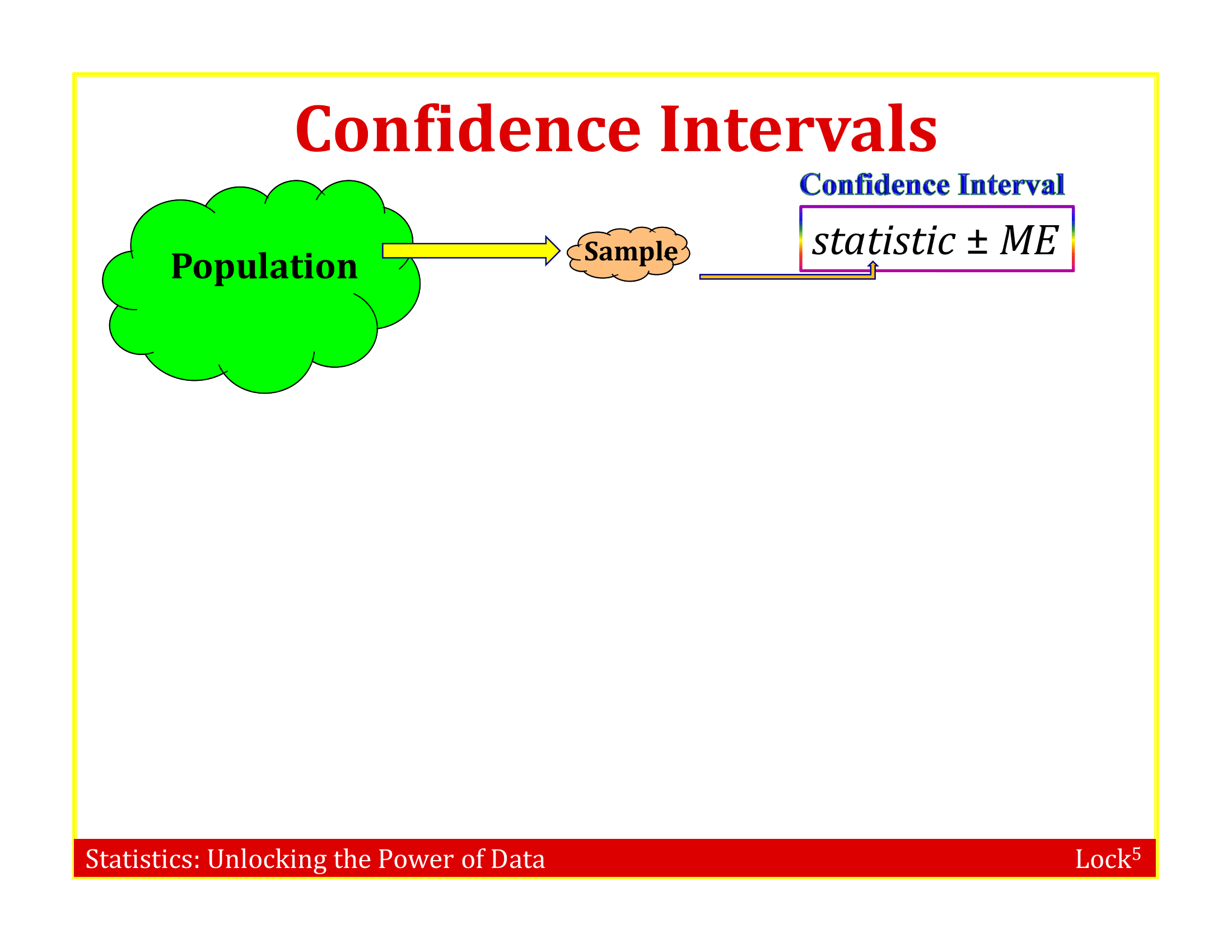
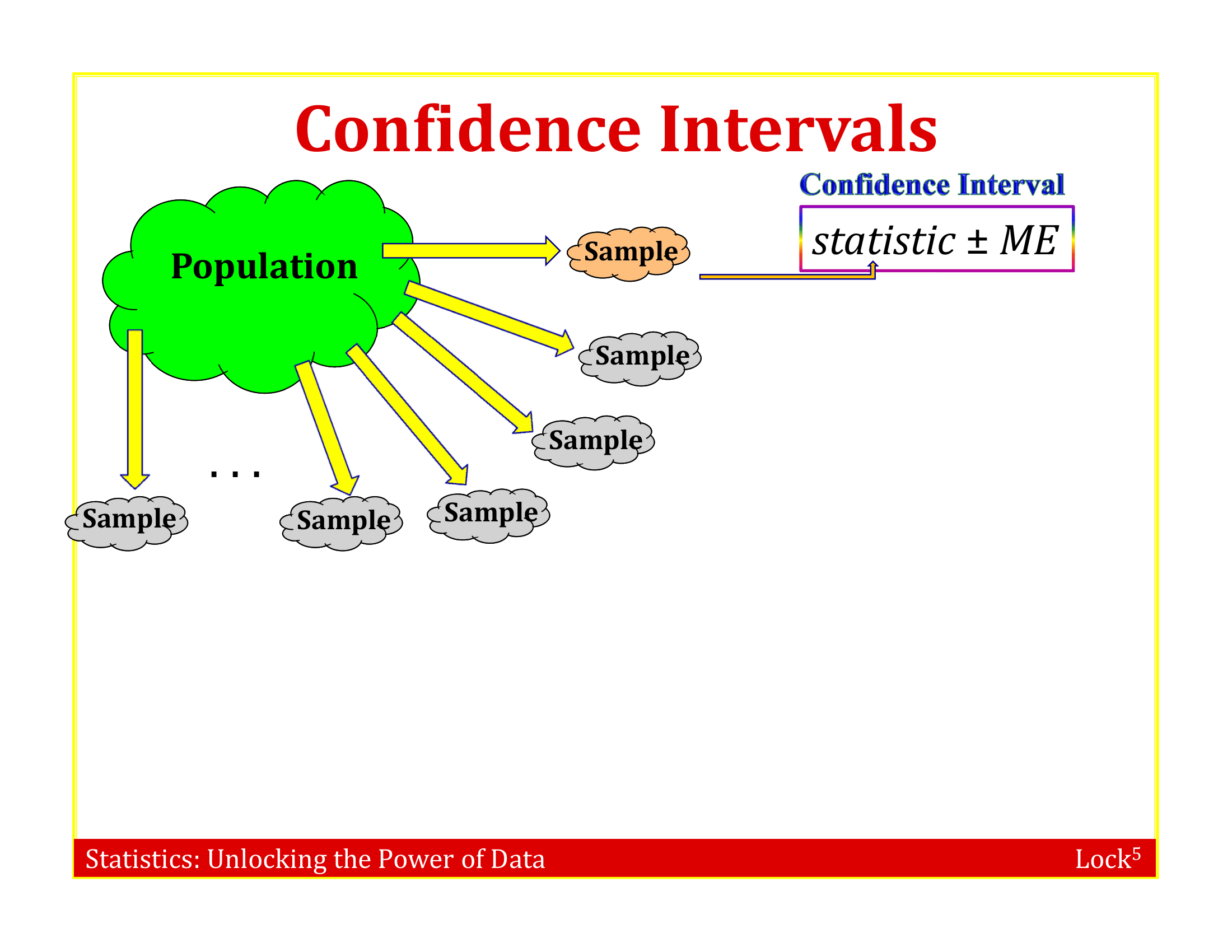
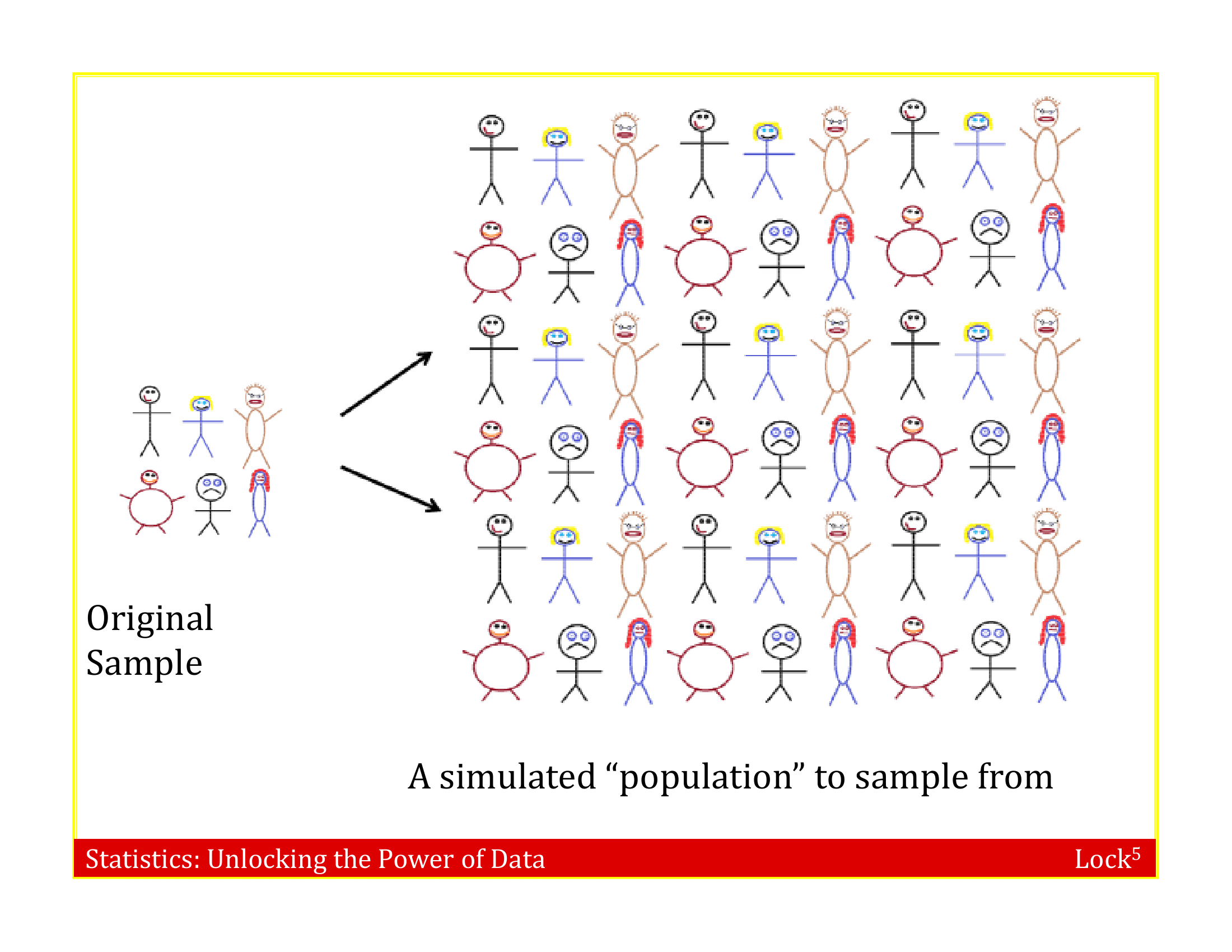
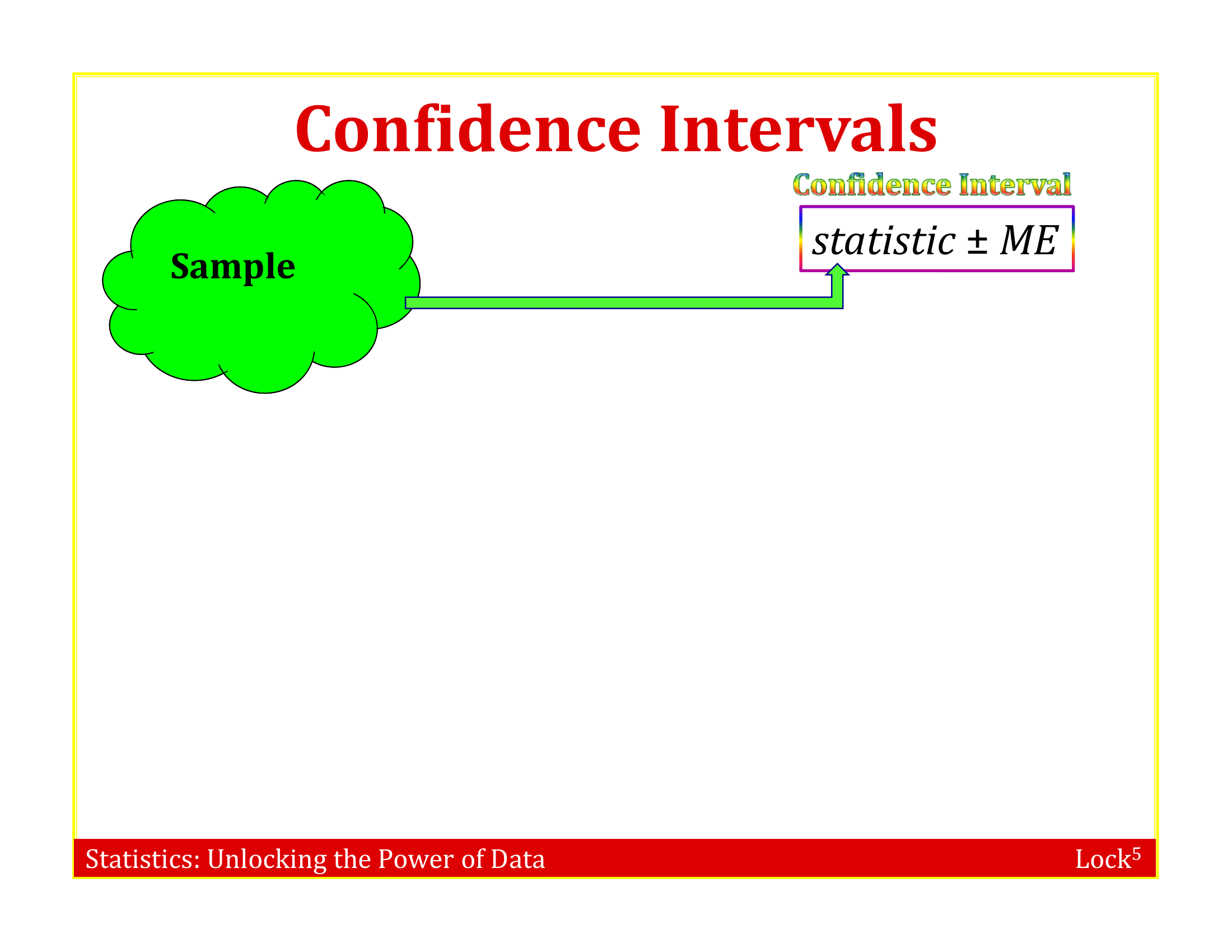
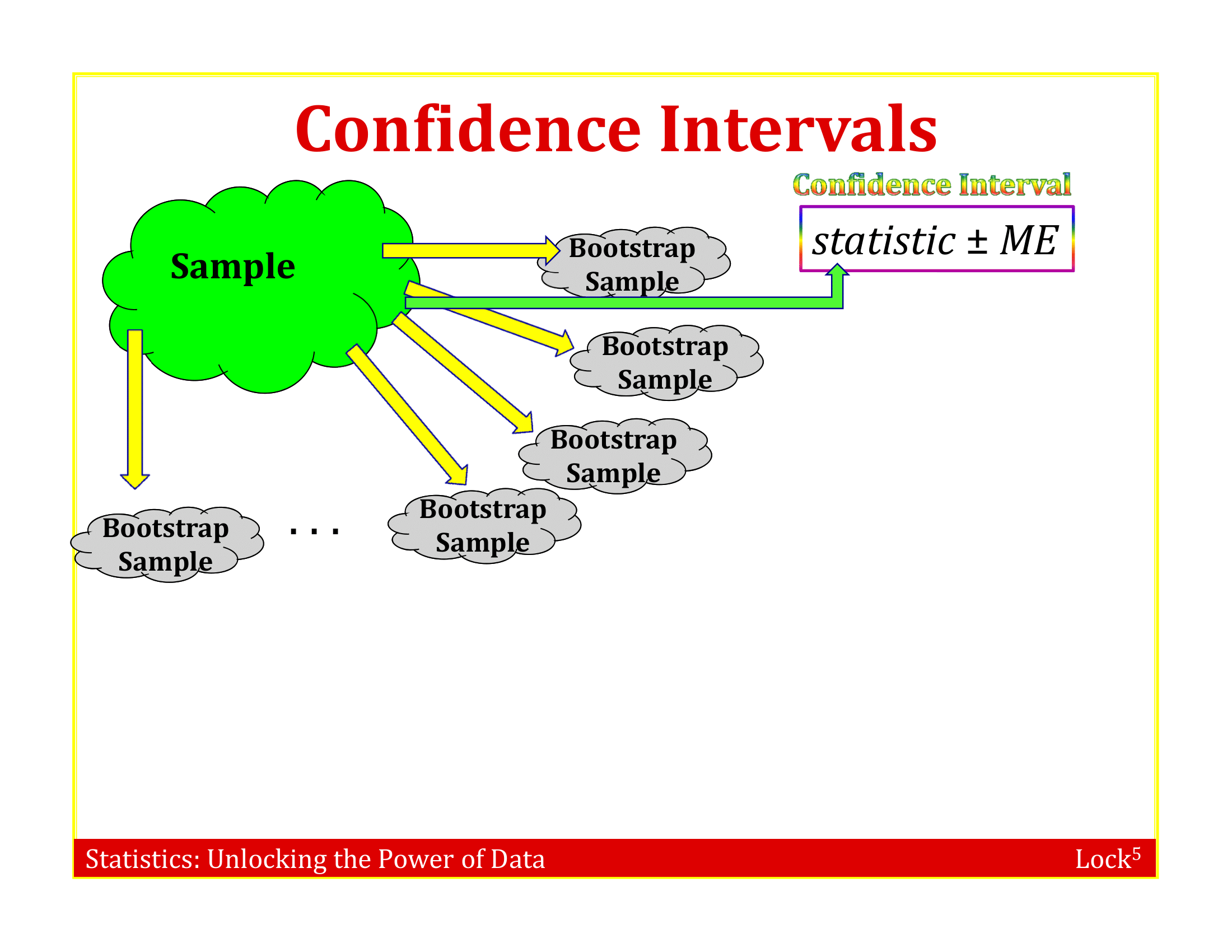
Imagine the “population” is many, many copies of the original sample
Resample this population many times and fit the model to each data set
What do you have to assume?
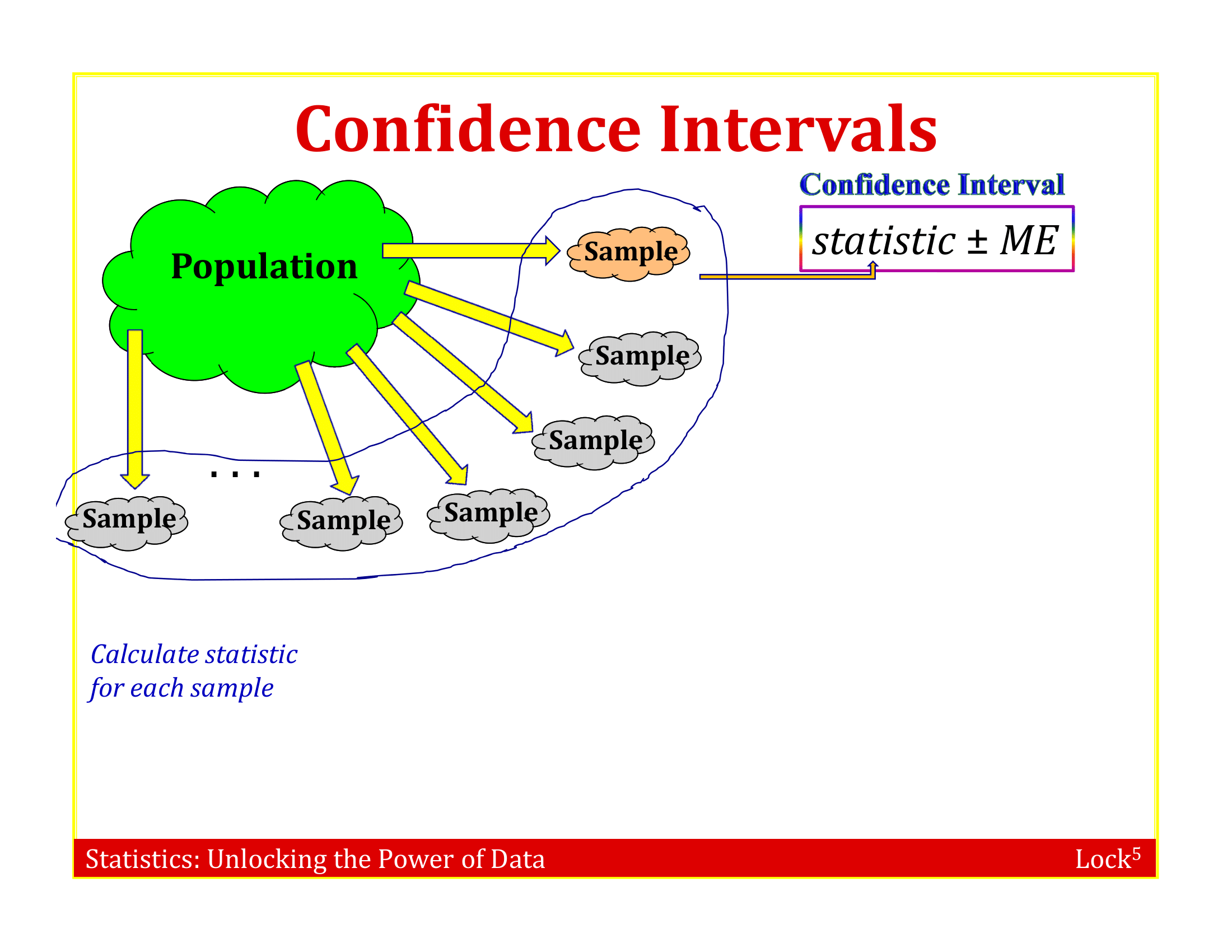
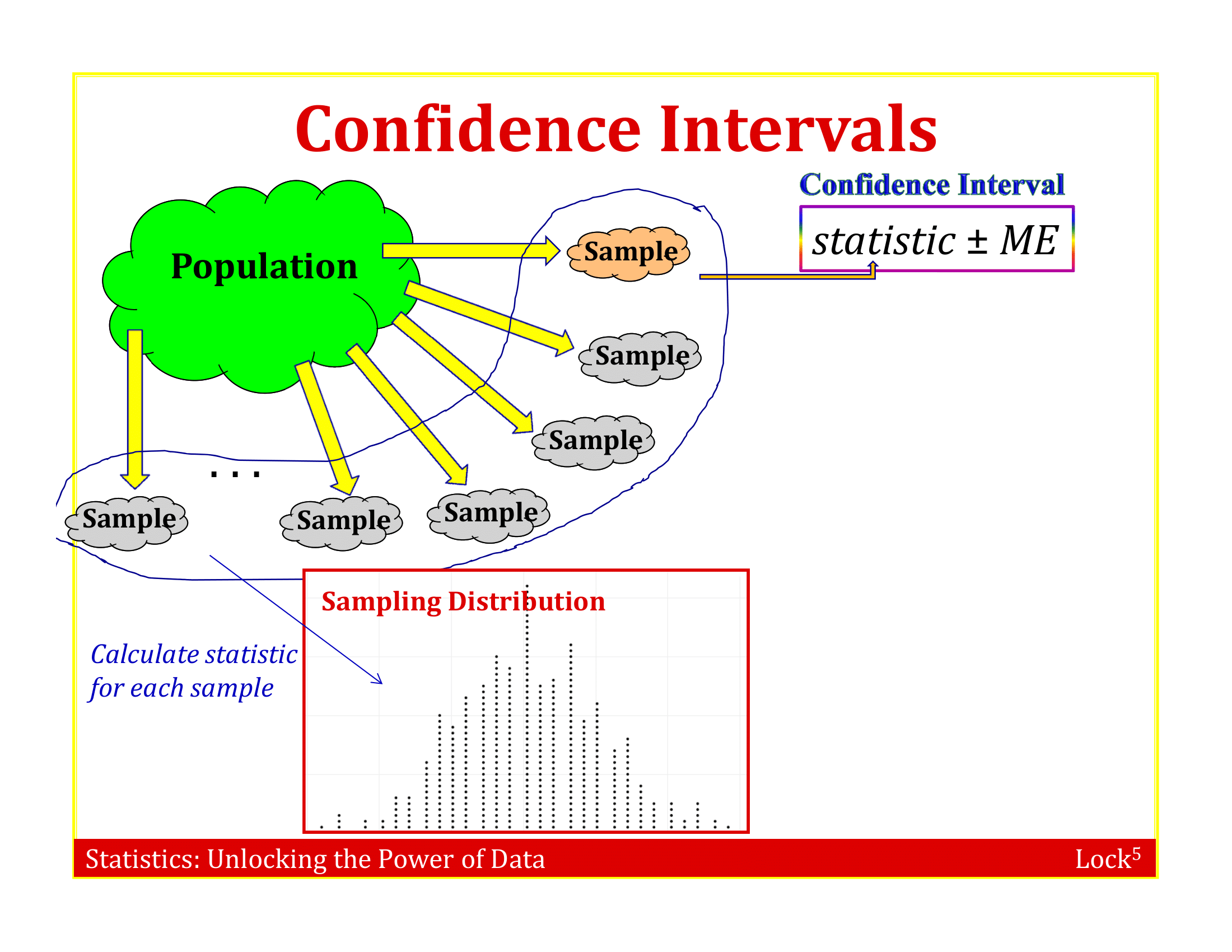
The sample is representative of the population (otherwise, its pointless to try to generalize from sample to population)
Suppose we have a random sample of 6 people:
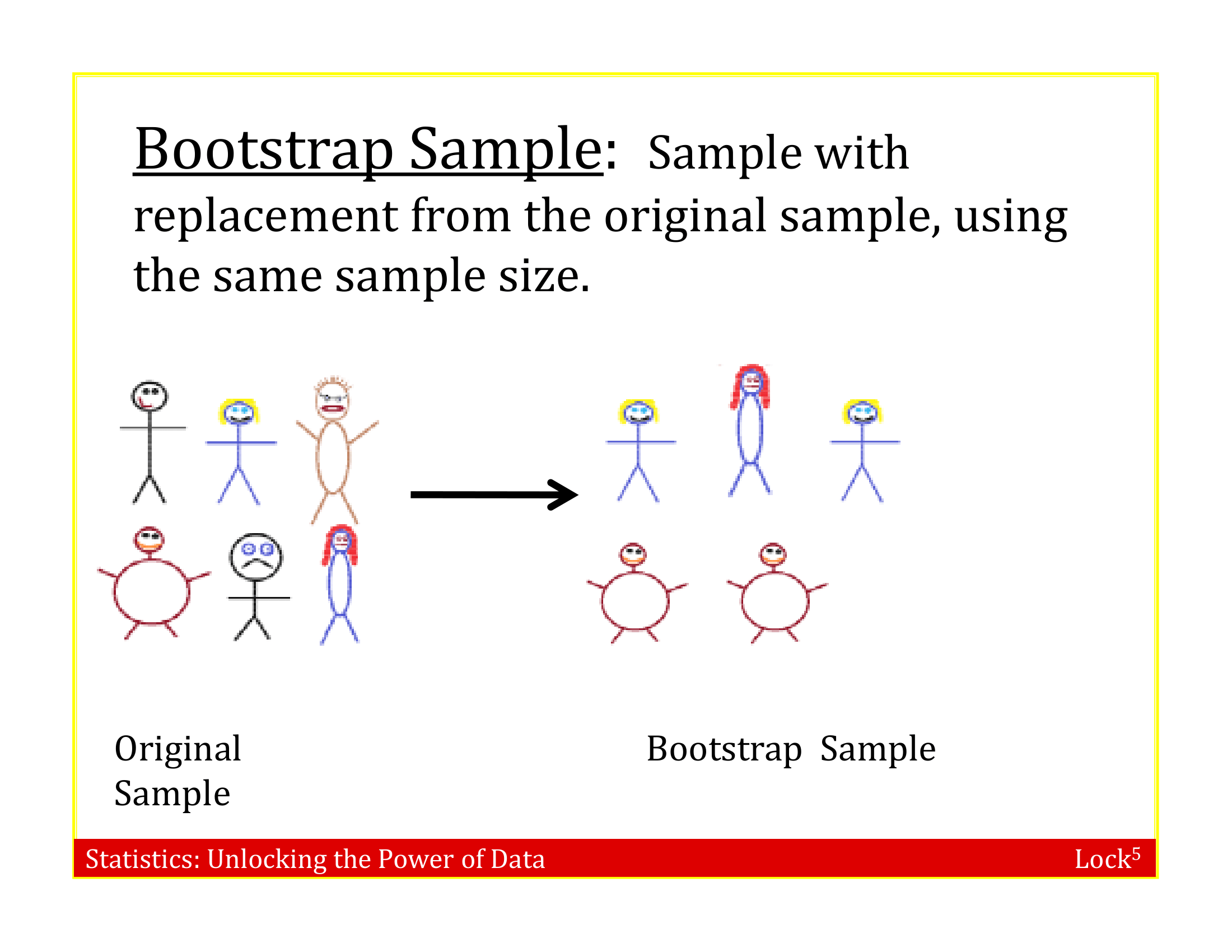
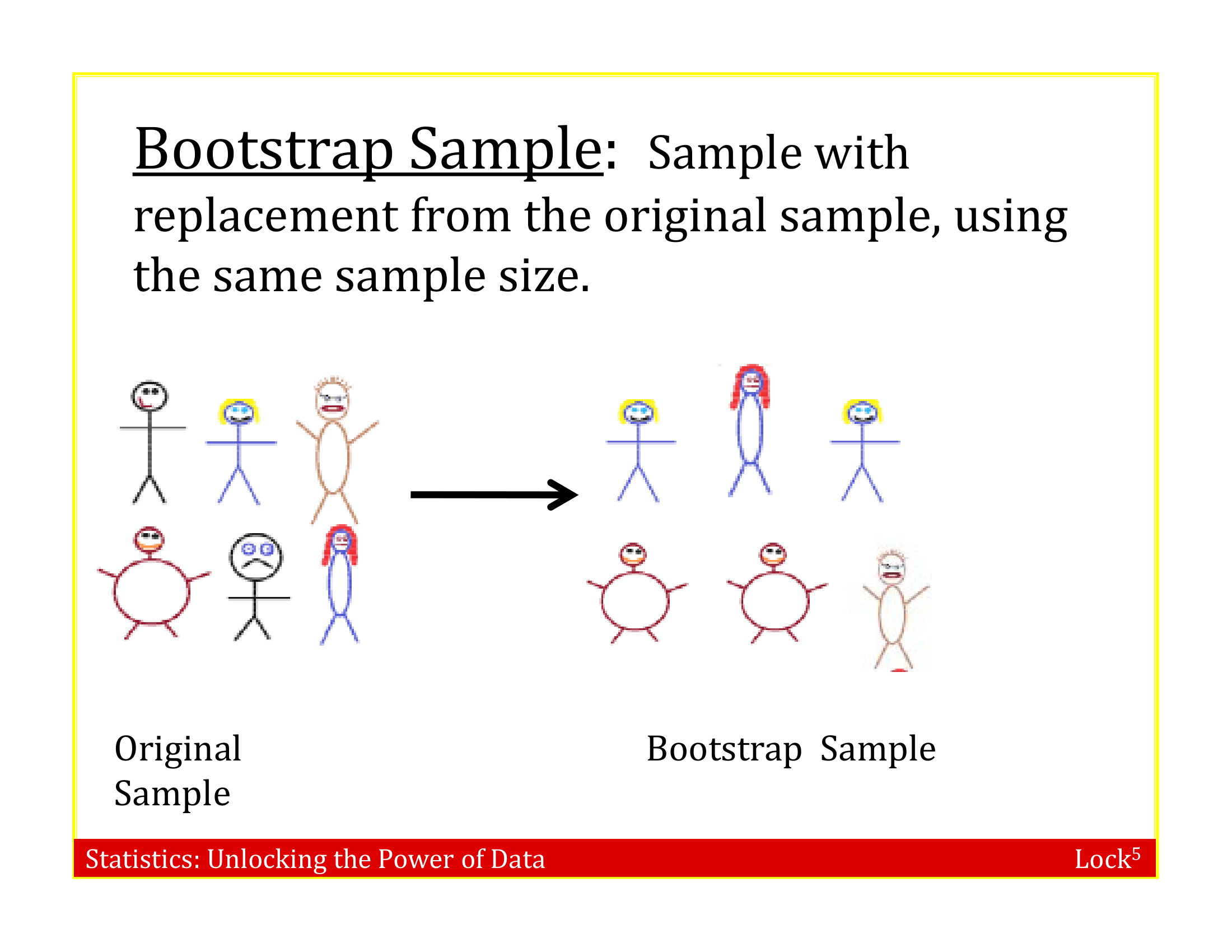
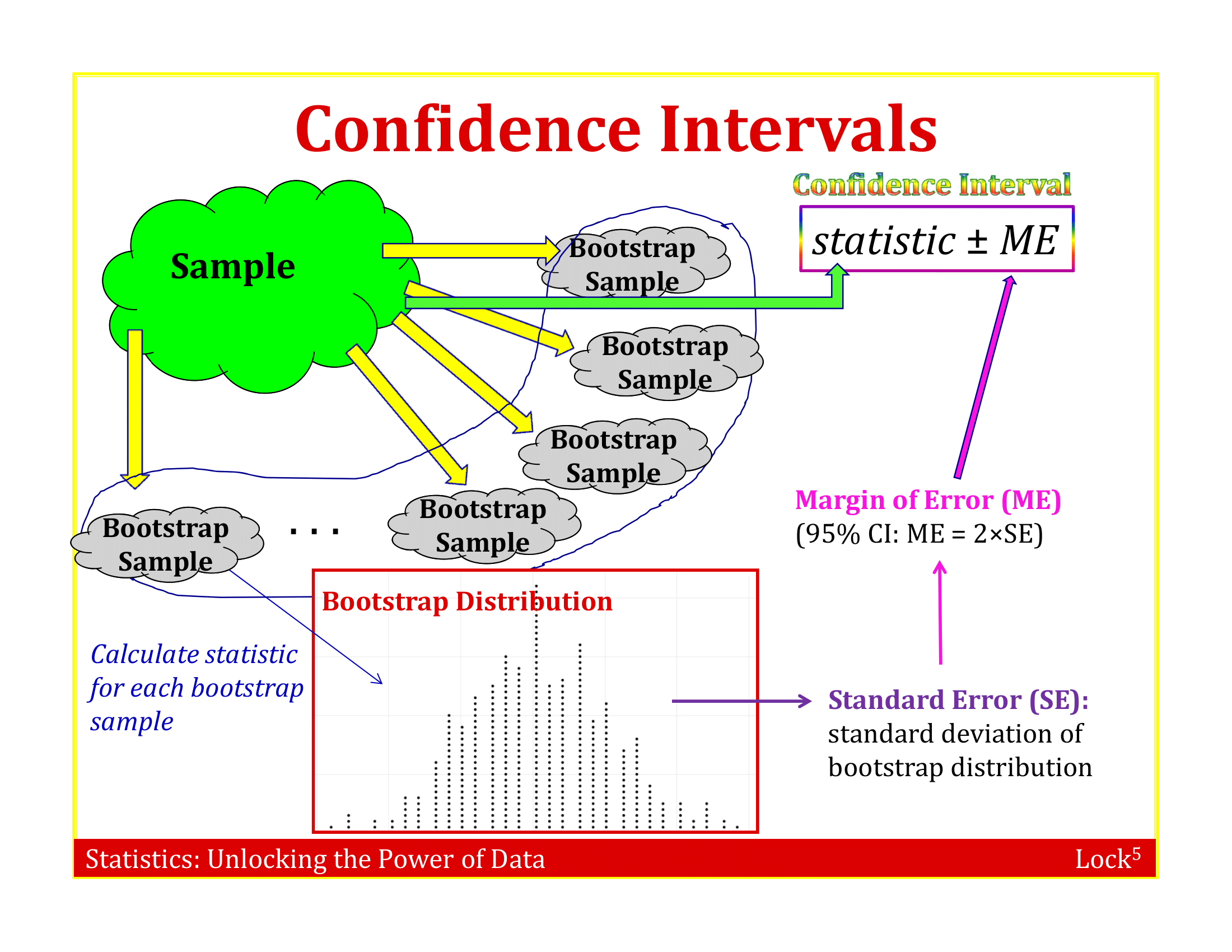
Sampling with Replacement
To simulate a sampling distribution, we can just take repeated random samples from this “population” made up of many copies of the sample
In practice, we can’t actually make infinite copies of the sample . . .
. . . but we can do this by sampling with replacement from the sample we have (each unit can be selected more than once)
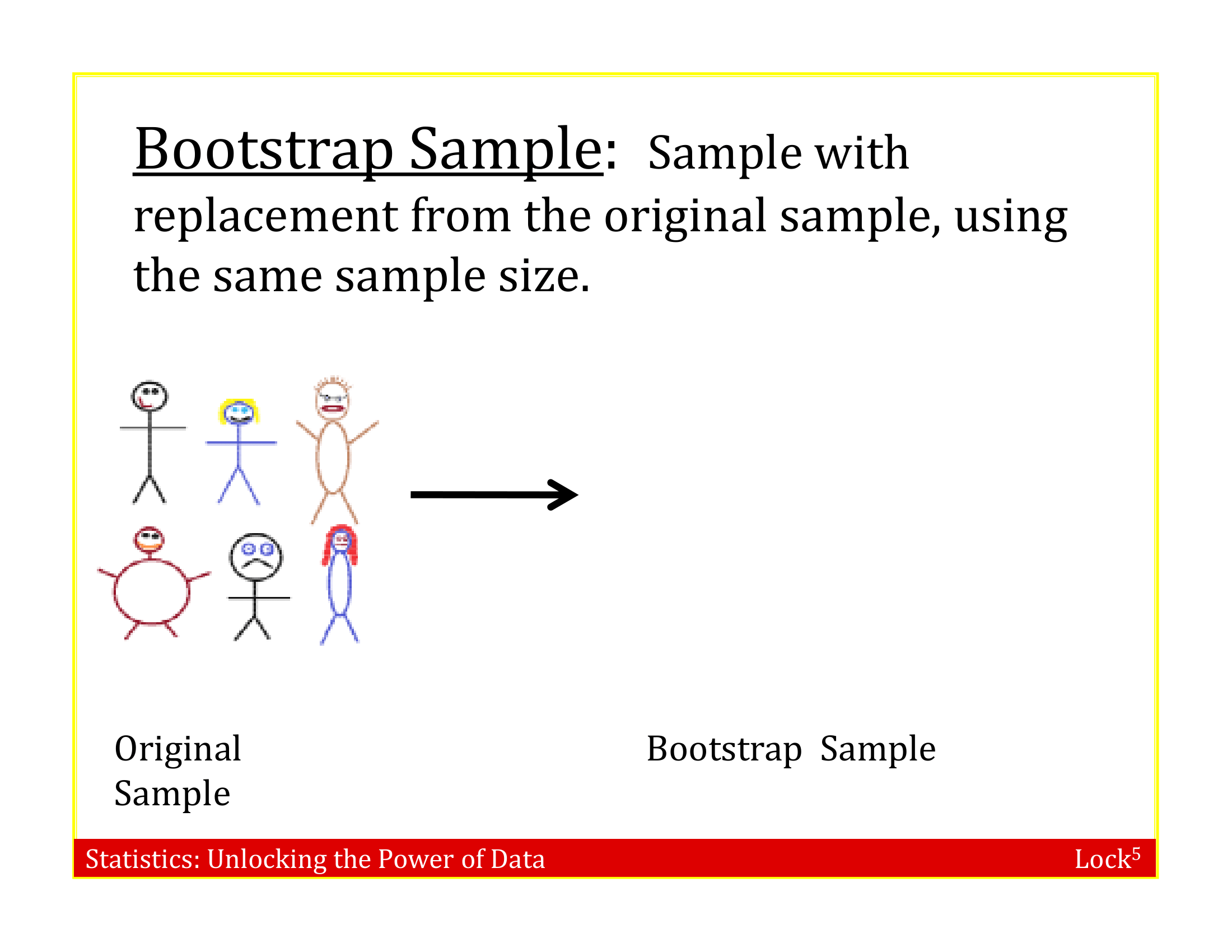
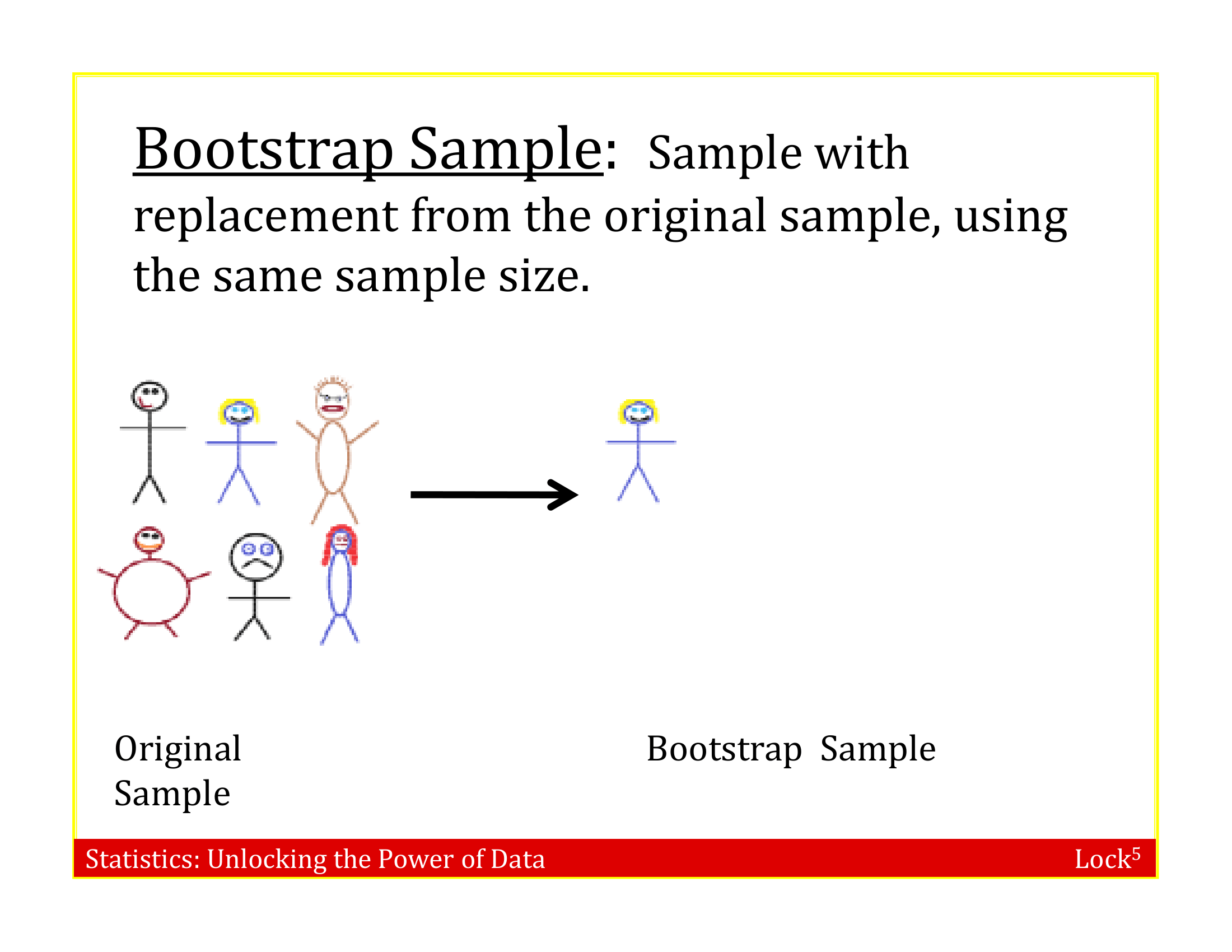
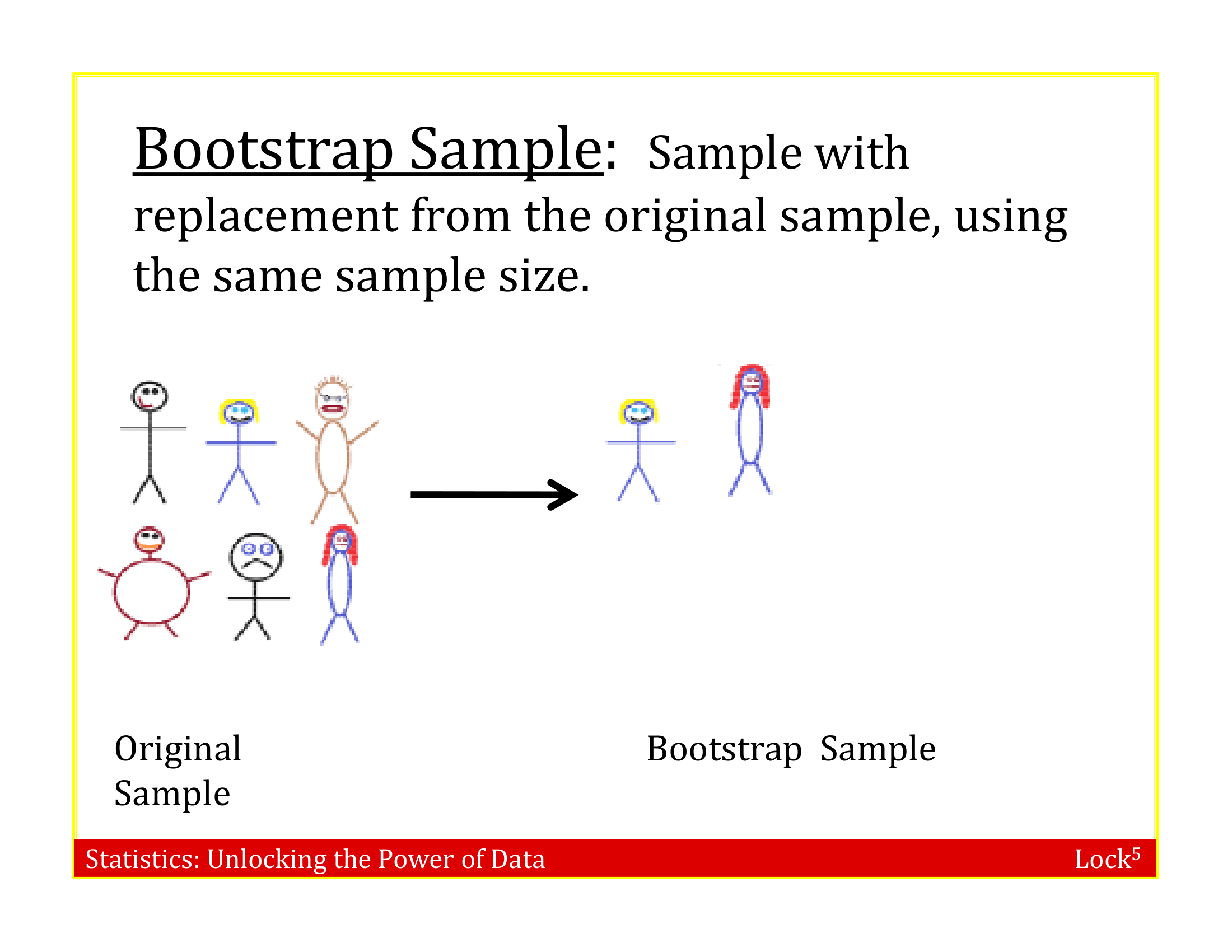
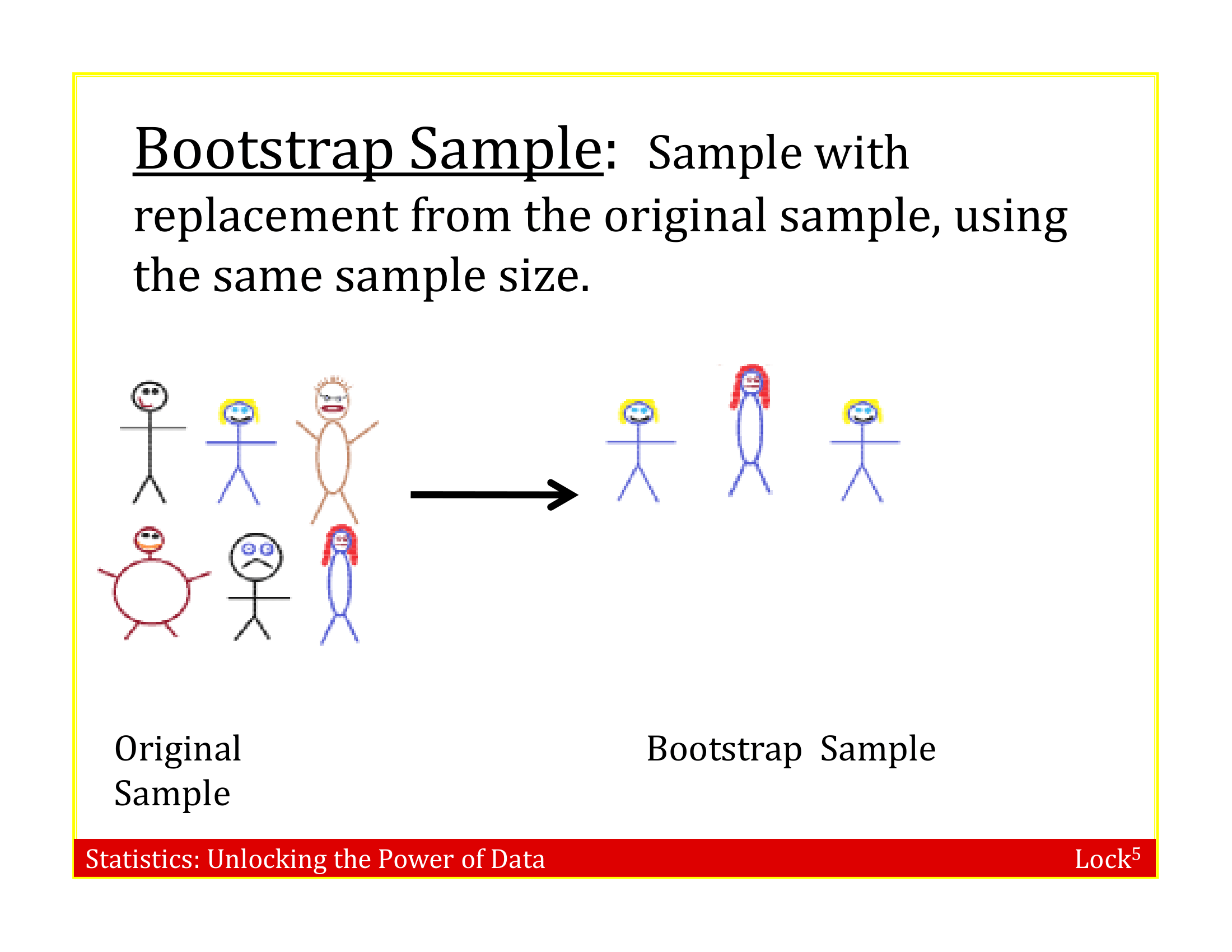
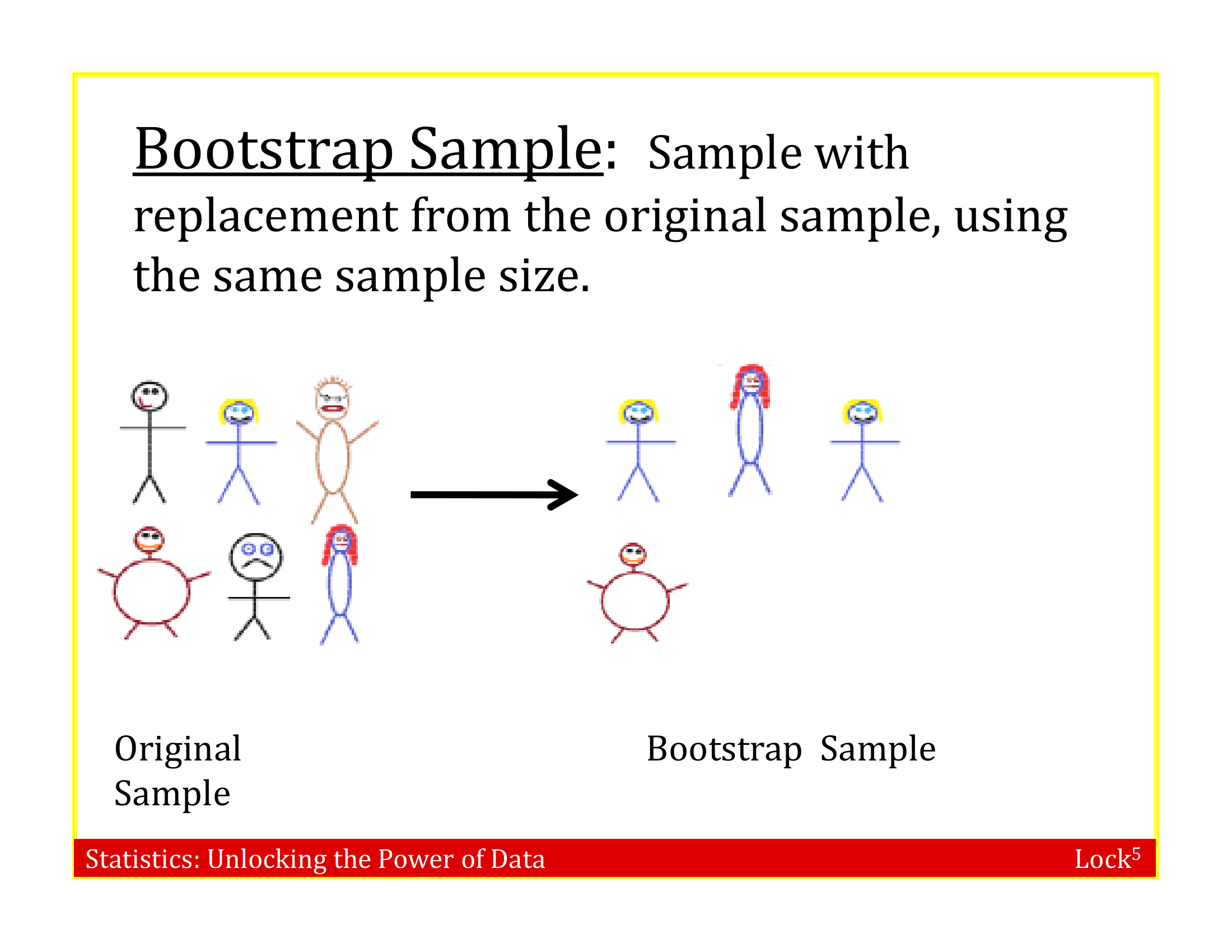
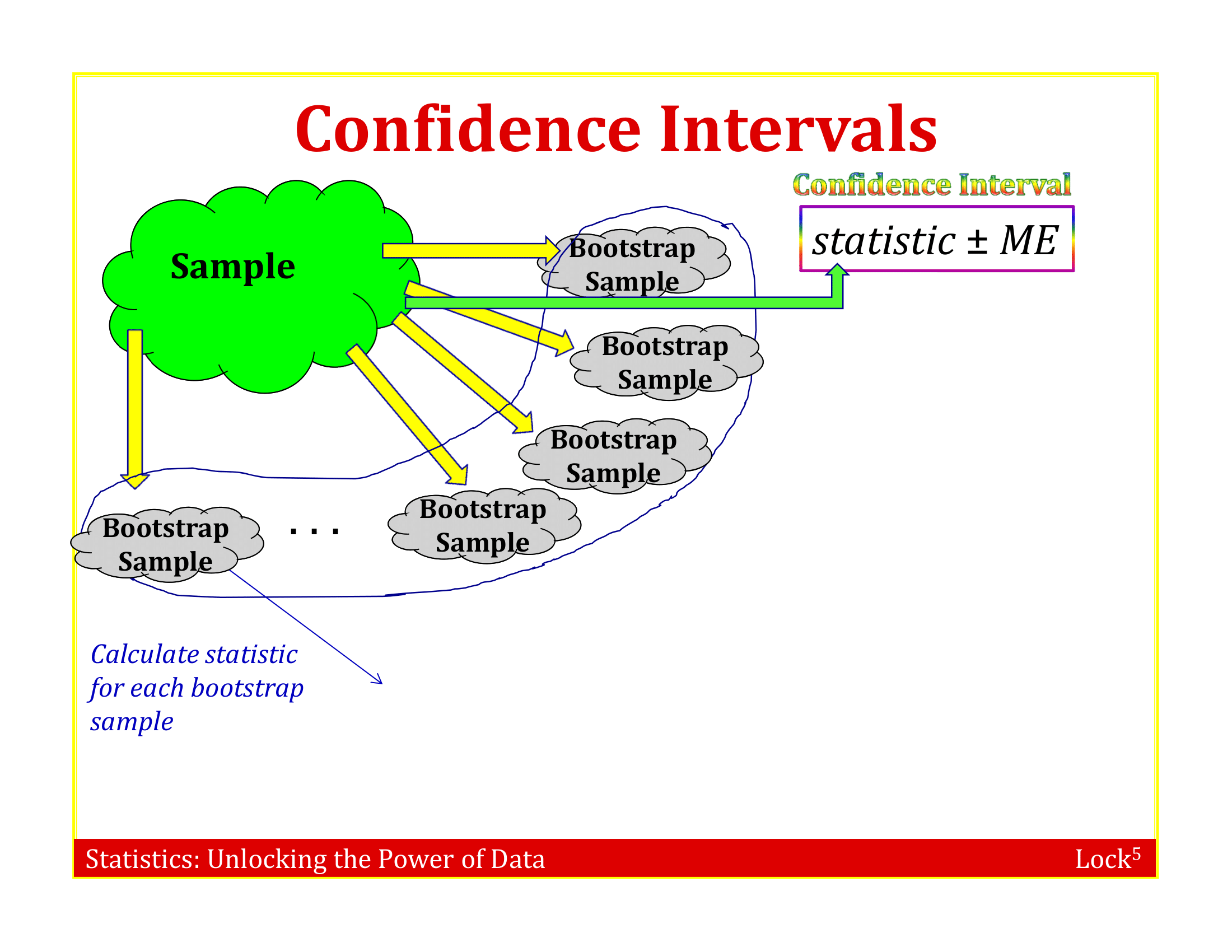
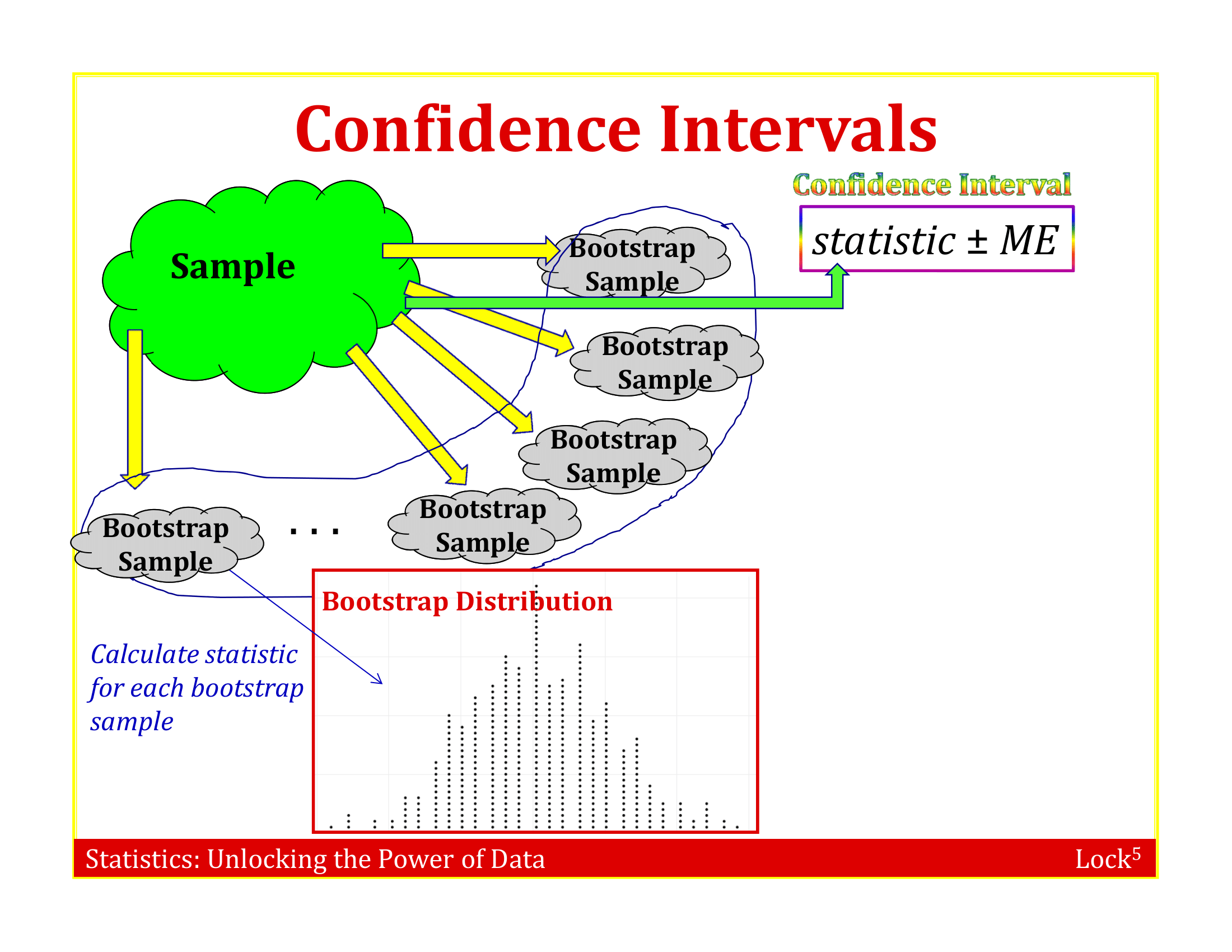
Bootstrap Sample
Your original sample has data values
18, 19, 19, 20, 21
Is the following a possible bootstrap sample: 18, 19, 20, 21, 22
No, 22 is not a value from the original sample
Is the following a possible bootstrap sample: 18, 19, 20, 21
NO, Bootstrap samples must be the same size as the original sample
Is the following a possible bootstrap sample: 18, 18, 19, 20, 21
YES. Same size, could be gotten by sampling with replacement
Bootstrap
A bootstrap sample is a random sample taken with replacement from the original sample, of the same size as the original sample
A bootstrap statistic is the statistic computed on a bootstrap sample
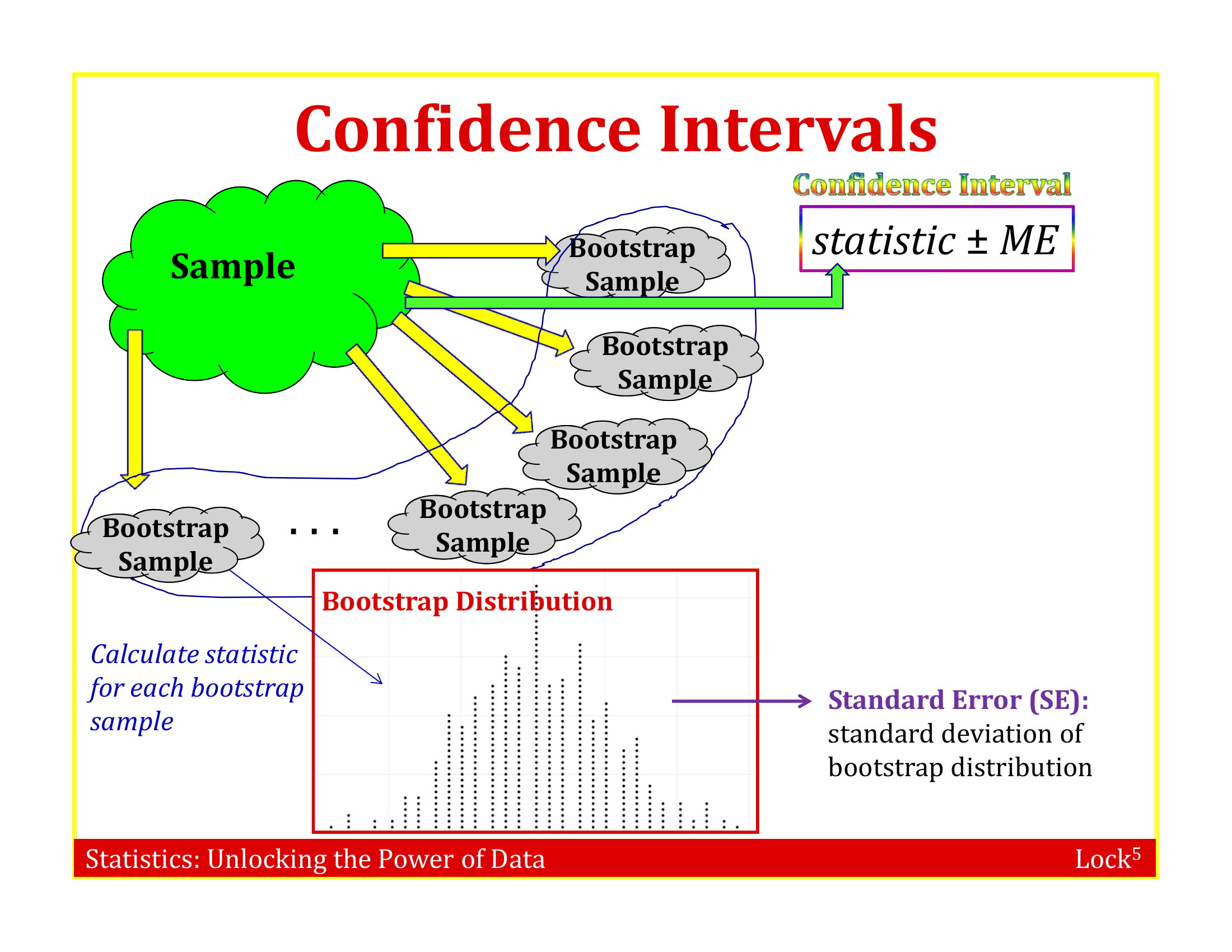
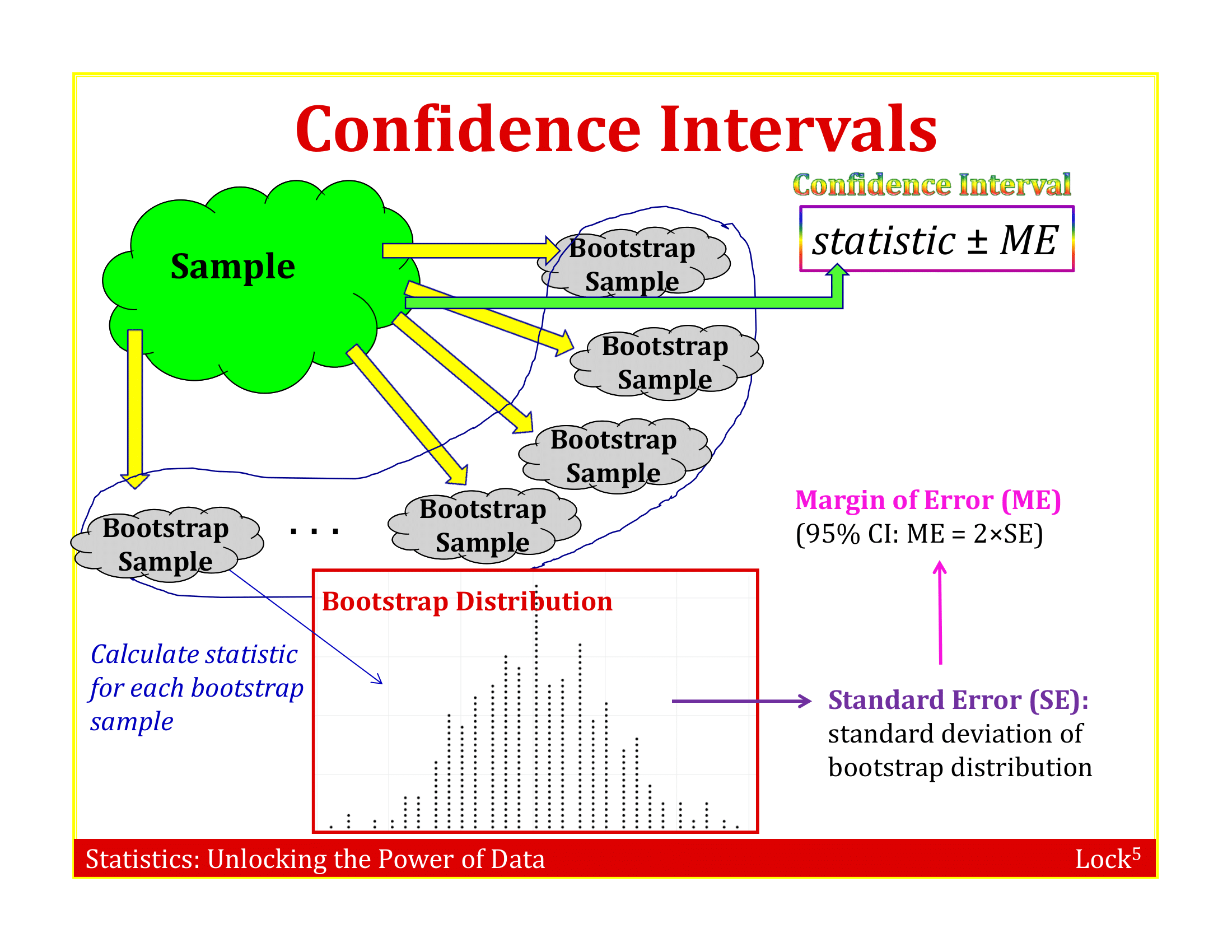
A bootstrap distribution is the distribution of many bootstrap statistics
Why “Bootstrap”?
“Pull yourself up by your bootstraps”
Lift yourself in the air simply by pulling up on the laces of your boots
Metaphor for accomplishing an “impossible” task without any outside help
Bootstrap versus Sampling Distribution
The sampling distribution should be centered on the population parameter
The bootstrap distribution should be centered on the sample statistic
Luckily, we don’t care about the center . . . we care about the variability!
Bootstrap versus Sampling Distribution
The variability of the bootstrap statistics should be similar to the variability of the sample statistics
The standard error of a statistic can be estimated using the standard deviation of the bootstrap distribution!
Mimic Original Sampling Design
What do we do if we have clustered data (multiple obs. on same sampling unit)?
Sample clusters with replacement (keeping all observations associated with the cluster)
Number of clusters in the bootstrap sample is the same as in the original sample
Treats “clusters” as independent
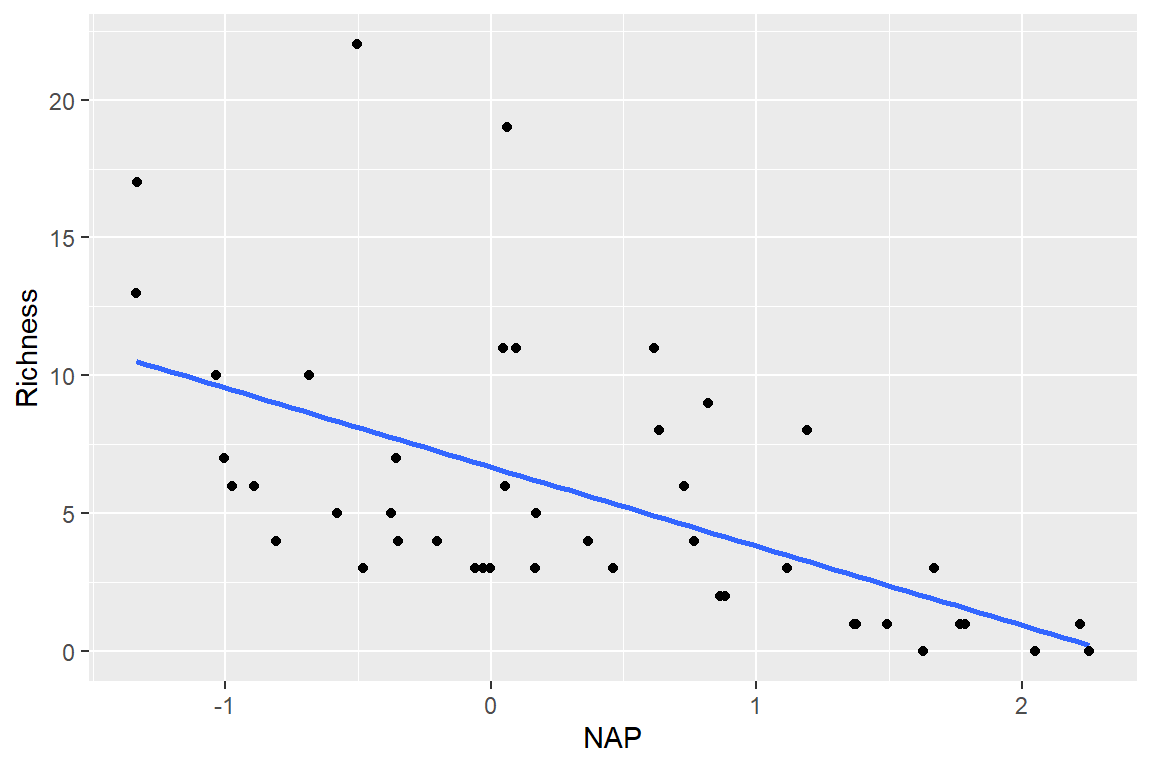
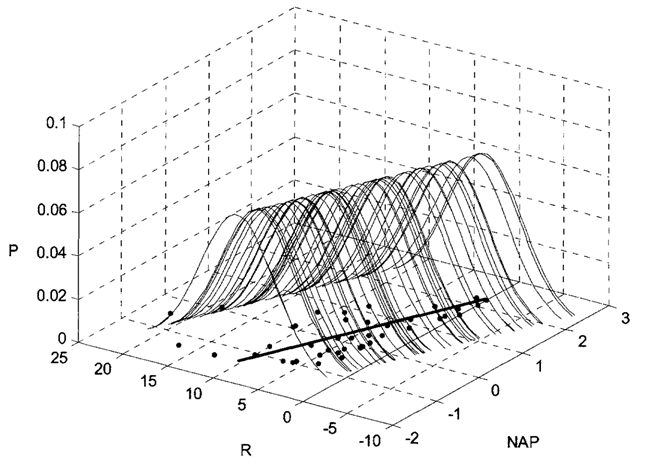
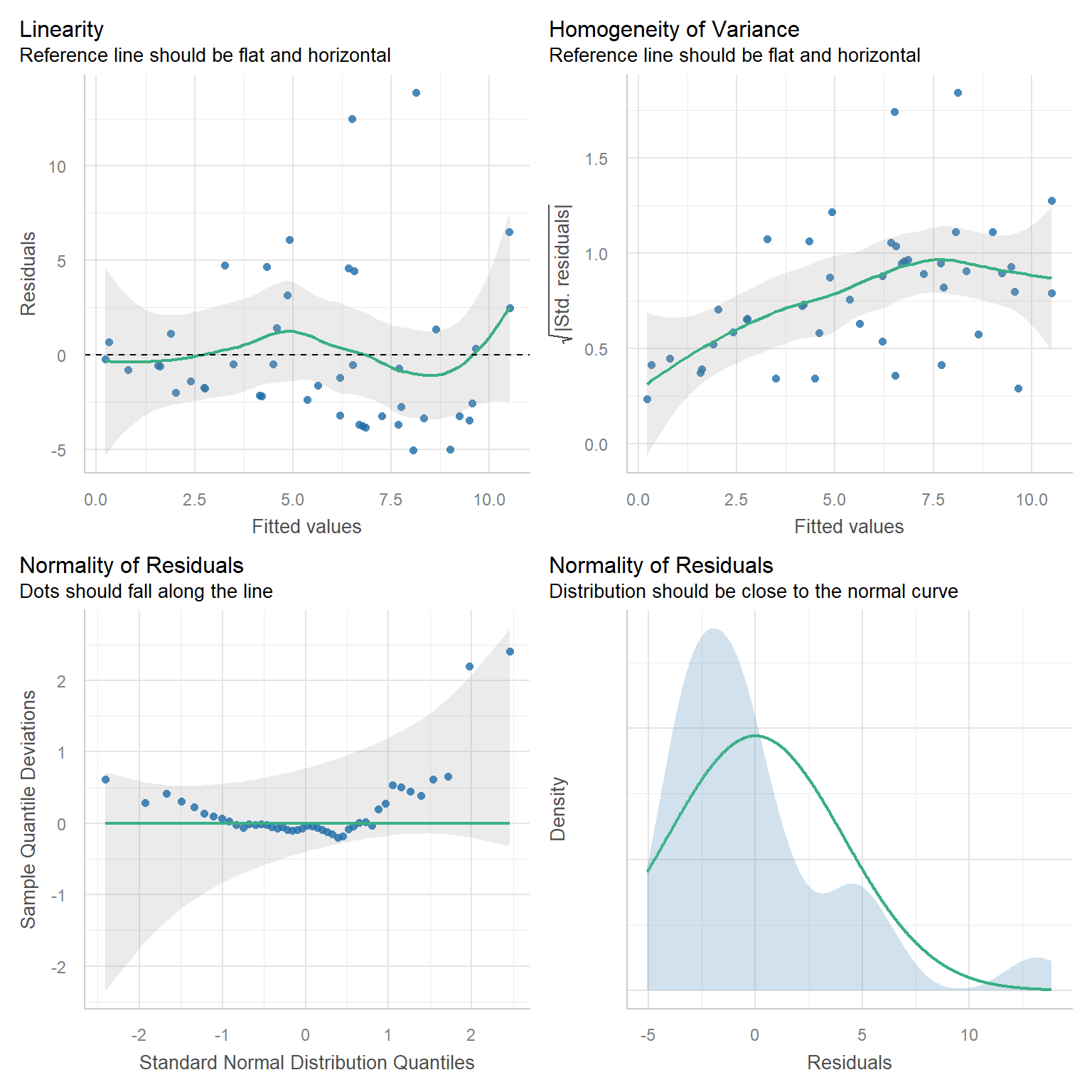
RIKZ Data - Bootstrapping
Cluster-level bootstrapping
Cluster-level bootstrap
This approach is most appropriate when:
clusters have equal numbers of observations (all have 5 in this case)
our interest lies in predictors that do not vary within a cluster
Example
The code below shows how you can get 1 bootstrap data set using cluster resampling:
# let's use the bootstrap to deal with non-constant variance and clustering uid<-unique(RIKZdat$Beach) nBeach<-length(uid)# Single bootstrap sample & fit (bootids<-data.frame(Beach=sample(uid, nBeach, replace=T)))