Call:
lm(formula = Richness ~ NAP, data = RIKZdat)
Residuals:
Min 1Q Median 3Q Max
-5.0675 -2.7607 -0.8029 1.3534 13.8723
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 6.6857 0.6578 10.164 5.25e-13 ***
NAP -2.8669 0.6307 -4.545 4.42e-05 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 4.16 on 43 degrees of freedom
Multiple R-squared: 0.3245, Adjusted R-squared: 0.3088
F-statistic: 20.66 on 1 and 43 DF, p-value: 4.418e-05
Mutliple Predictors and RIKZ data
Assuming, naively, that observations are independent, we see that there is a relationship between Richness (\(\mathrm{R}\)) and relative elevation (\(\mathrm{NAP}\)):
\(\beta_0\): the expected level of Richness if Humus and NAP both equal 0.
\(\beta_1\): the change in expected Richness for every 1 unit increase in NAP while holding Humus constant
\(\beta_2\): the change in expected Richness for every 1 unit increase in Humus while holding NAP constant.
Multiple Linear Regression
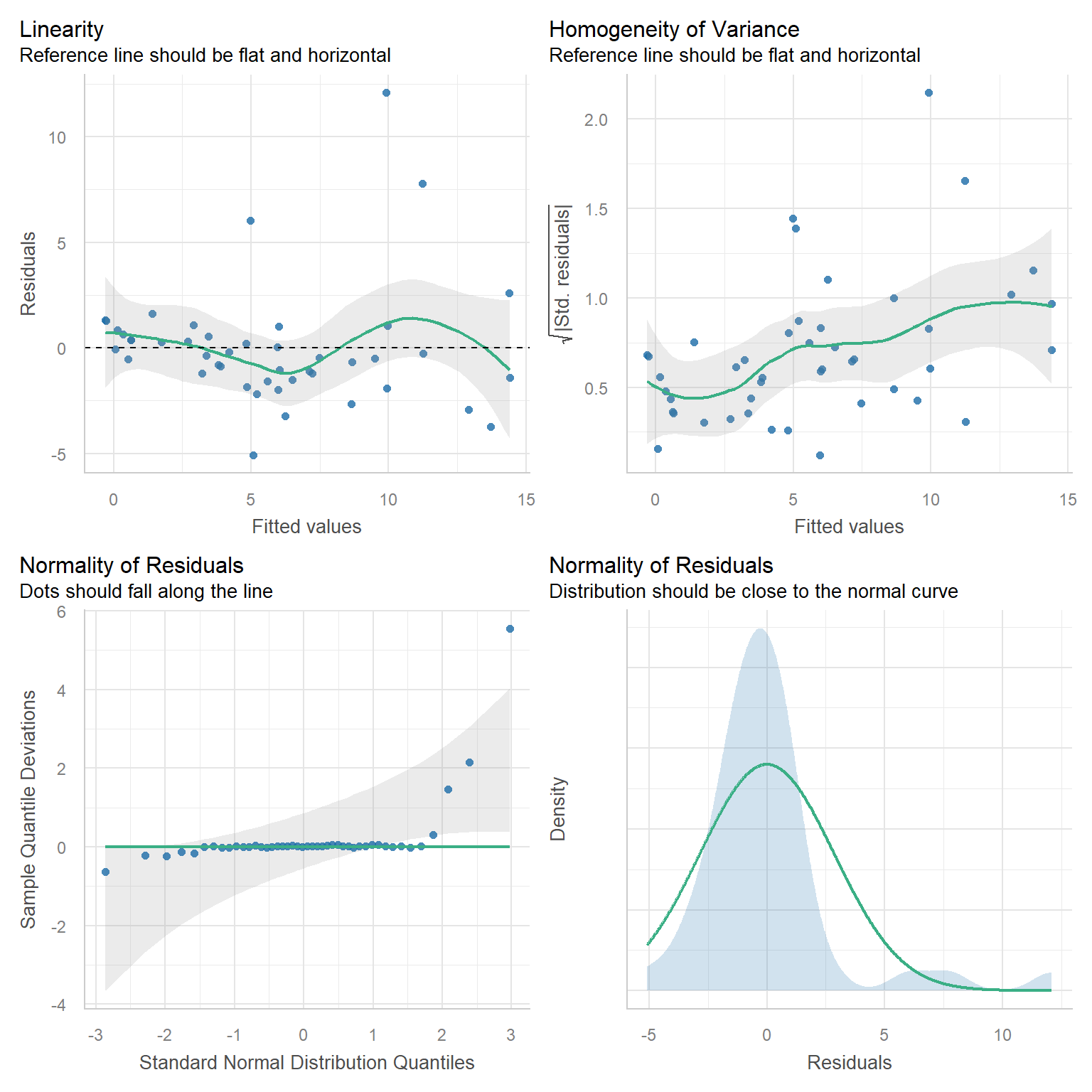
We have the same assumptions (HILE Gauss) and can use the same diagnostic plots.
However, it’s important to diagnose the degree to which explanatory variables are correlated with each other (will address in more detail when we cover multicollinearity).
The Coefficient of Determination (R\(^2= SSR/SST\)) is calculated the same way, with:
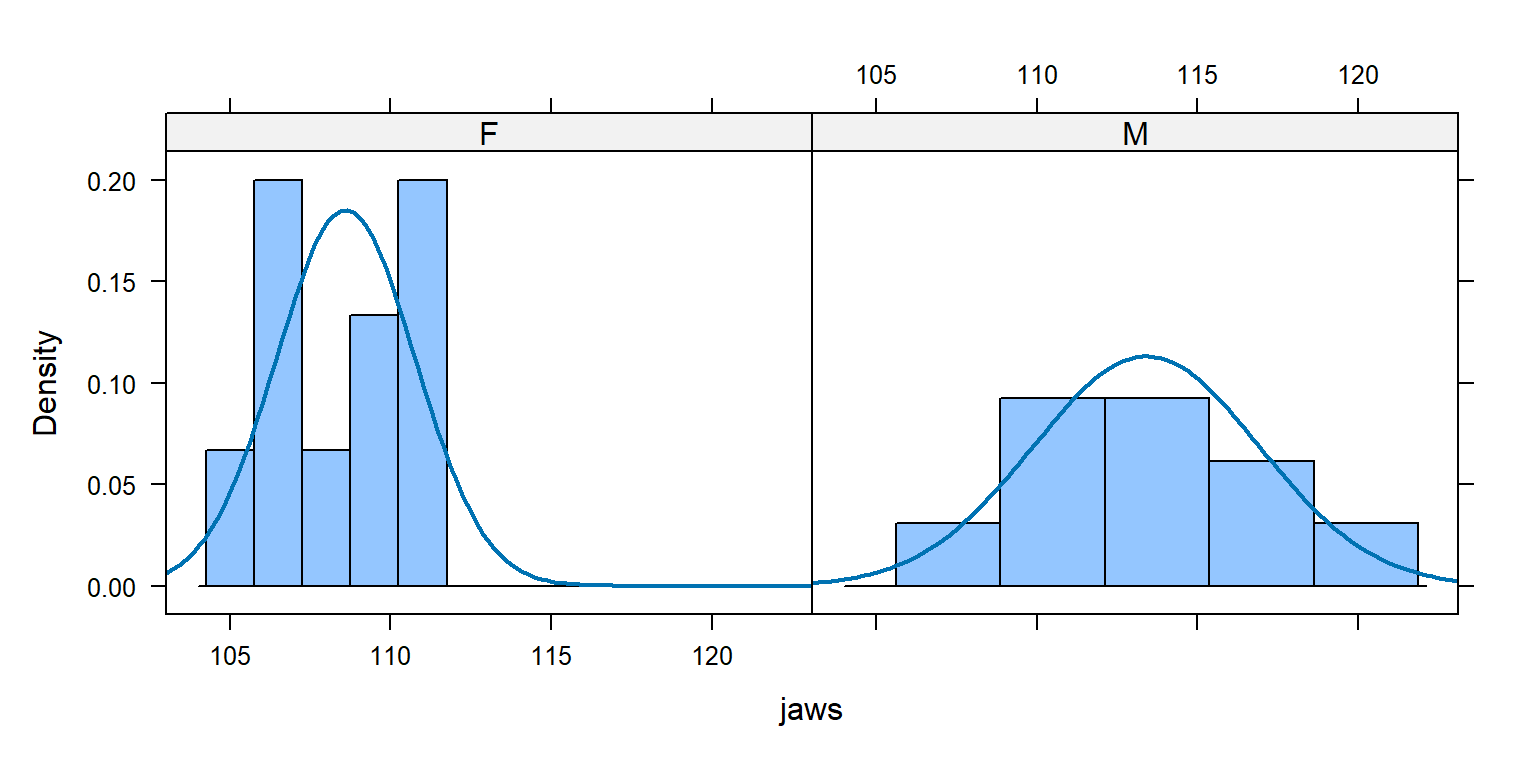
Two Sample t-test
data: males and females
t = 3.4843, df = 18, p-value = 0.002647
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
1.905773 7.694227
sample estimates:
mean of x mean of y
113.4 108.6
Categorical Variables
We can also test the effect of jackal sex on mandible lengths with a regression model.
We have to create a data.frame with mandible lengths (quantitative) and sex (categorical)
Two Sample t-test
data: males and females
t = 3.4843, df = 18, p-value = 0.002647
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
1.905773 7.694227
sample estimates:
mean of x mean of y
113.4 108.6
Later, we will see how we can relax these assumptions (using either JAGS or gls in the nlme package).
Categorical variables
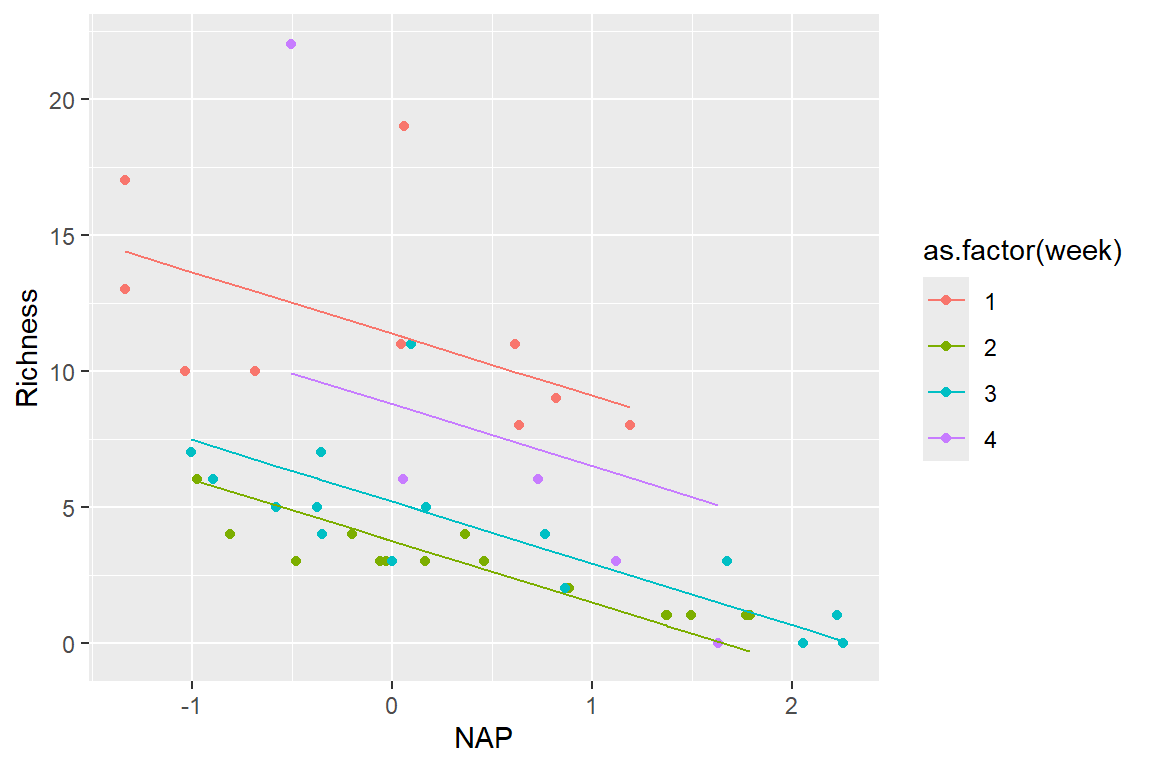
Recall the RIKZ data.
Assuming, naively, that observations are independent, we already established the relationship between Richness (\(\mathrm{R}\)) and relative elevation (\(\mathrm{NAP}\)): \[\begin{equation*}
\hat{\mathrm{R}}_i= \hat{\mu}_i = 6.886-2.867\mathrm{NAP}_i
\end{equation*}\]
Now, what if we also suspected that the Week the data were collected might affect Richness in addition to NAP?
Week could be considered continuous, but probably better to analyze it as a nominal variable with 4 categories.
How many dummy variables will we need to have in order to analyze the effect of Week?
3 (we have 4 groups)
In R, use as.factor(week) to convert to a nominal variable.
There is one slope (\(\beta_1\)) relating to the effect of NAP on Richness. In addition, each Week gets its own intercept:
Week 1: \(\mu_i = \beta_2 + \beta_1X_{NAP,i}\)
Week 2: \(\mu_i = \beta_3 + \beta_1X_{NAP,i}\)
Week 3: \(\mu_i = \beta_4 + \beta_1X_{NAP,i}\)
Week 4: \(\mu_i = \beta_5 + \beta_1X_{NAP,i}\)
Reference vs. Means Coding
lmfit.ancova.r <-lm(Richness ~ NAP +as.factor(week), data = RIKZdat) summary(lmfit.ancova.r)
Call:
lm(formula = Richness ~ NAP + as.factor(week), data = RIKZdat)
Residuals:
Min 1Q Median 3Q Max
-5.0788 -1.4014 -0.3633 0.6500 12.0845
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 11.3677 0.9459 12.017 7.48e-15 ***
NAP -2.2708 0.4678 -4.854 1.88e-05 ***
as.factor(week)2 -7.6251 1.2491 -6.105 3.37e-07 ***
as.factor(week)3 -6.1780 1.2453 -4.961 1.34e-05 ***
as.factor(week)4 -2.5943 1.6694 -1.554 0.128
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.987 on 40 degrees of freedom
Multiple R-squared: 0.6759, Adjusted R-squared: 0.6435
F-statistic: 20.86 on 4 and 40 DF, p-value: 2.369e-09
lmfit.ancova.m <-lm(Richness ~ NAP +as.factor(week)-1, data = RIKZdat) summary(lmfit.ancova.m)
Call:
lm(formula = Richness ~ NAP + as.factor(week) - 1, data = RIKZdat)
Residuals:
Min 1Q Median 3Q Max
-5.0788 -1.4014 -0.3633 0.6500 12.0845
Coefficients:
Estimate Std. Error t value Pr(>|t|)
NAP -2.2708 0.4678 -4.854 1.88e-05 ***
as.factor(week)1 11.3677 0.9459 12.017 7.48e-15 ***
as.factor(week)2 3.7426 0.8026 4.663 3.44e-05 ***
as.factor(week)3 5.1897 0.7979 6.505 9.24e-08 ***
as.factor(week)4 8.7734 1.3657 6.424 1.20e-07 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.987 on 40 degrees of freedom
Multiple R-squared: 0.8604, Adjusted R-squared: 0.843
F-statistic: 49.32 on 5 and 40 DF, p-value: 4.676e-16
Interactions
We should be cautious with interactions:
In experimental data, interactions should frequently be examined, and often should be examined before testing for main effects.
In observational studies, data will usually be unbalanced. Interactions should rarely be examined unless though to be important a priori.
Interactions
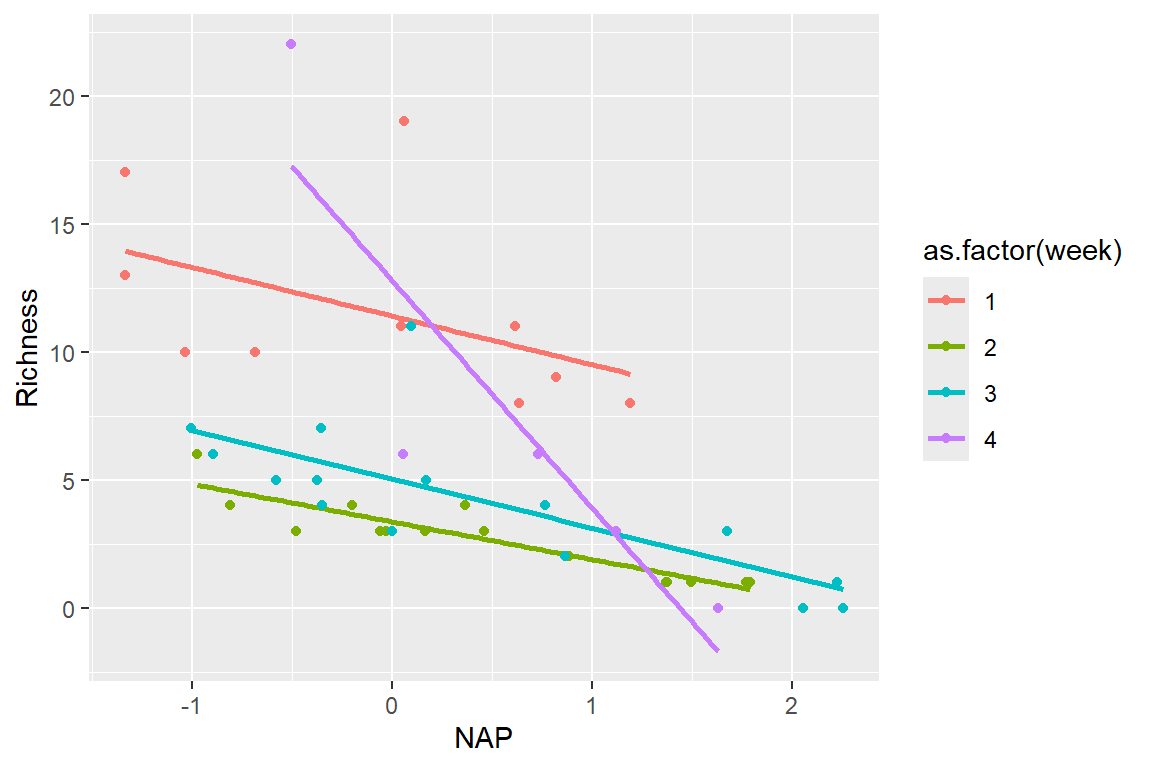
For illustration only, we can naively assume that we think that NAP and Week interact in their effects on Richness.
Caveat: there’s no real biological reason that week and relative elevation should interact, and the researchers did not design this experiment to test for this interaction.
lmfit.ancovaI <-lm(Richness ~ NAP *as.factor(week), data = RIKZdat)summary(lmfit.ancovaI)
Call:
lm(formula = Richness ~ NAP * as.factor(week), data = RIKZdat)
Residuals:
Min 1Q Median 3Q Max
-6.3022 -0.9442 -0.2946 0.3383 7.7103
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 11.40561 0.77730 14.673 < 2e-16 ***
NAP -1.90016 0.87000 -2.184 0.035369 *
as.factor(week)2 -8.04029 1.05519 -7.620 4.30e-09 ***
as.factor(week)3 -6.37154 1.03168 -6.176 3.63e-07 ***
as.factor(week)4 1.37721 1.60036 0.861 0.395020
NAP:as.factor(week)2 0.42558 1.12008 0.380 0.706152
NAP:as.factor(week)3 -0.01344 1.04246 -0.013 0.989782
NAP:as.factor(week)4 -7.00002 1.68721 -4.149 0.000188 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 2.442 on 37 degrees of freedom
Multiple R-squared: 0.7997, Adjusted R-squared: 0.7618
F-statistic: 21.11 on 7 and 37 DF, p-value: 3.935e-11
Anova Table (Type II tests)
Response: Richness
Sum Sq Df F value Pr(>F)
NAP 231.59 1 27.1999 6.335e-06 ***
exposure 24.94 1 2.9289 0.09495 .
as.factor(week) 73.19 3 2.8654 0.04888 *
Residuals 332.07 39
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Multiple df test tests whether all 3 coefficients associated with as.factor(week) are 0 versus the alternative hypothesis that at least 1 is non-zero (all weeks are the same vs. at least one of the weeks differs from the others).
Anova versus anova
For continuous variables, the p-values from Anova will be identical to the t-test p-values (see exposure variable).
These tests for (NAP, exposure, week) are conditional on having the other terms included in the model.
By contrast the anova function which performs “sequential” tests (where, “order of entry” matters!)
Analysis of Variance Table
Response: Richness
Df Sum Sq Mean Sq F value Pr(>F)
as.factor(week) 3 534.31 178.104 20.9177 3.060e-08 ***
exposure 1 3.67 3.675 0.4316 0.5151
NAP 1 231.59 231.593 27.1999 6.335e-06 ***
Residuals 39 332.07 8.514
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Additional Notes
See section 3.8 in the book for information on how to conduct pairwise comparisons (e.g., we have “4 choose 2” = 6 possible comparisons of different weeks).
See sections 3.12 and 3.13 for information regarding how to test your own hypotheses using contrasts (formed by taking linear combinations of the regression coefficients).
For example, we could test whether the average richness during weeks 1 and 2 differs from the average richness of weeks 3 and 4.
Summary
Understand regression analysis with matrix notation.
Become familiar with creating dummy variables for categorical regressors
Interpret the results of regression analyses with categorical and quantitative variables